Markdowner:将任意网站转换为LLM可用的Markdown数据工具
Markdowner 是一个快速工具,可以将任何网站转换为 LLM 可用的 Markdown 数据,让开发者轻松实现内容存储与查询。

- defagi
- 1 min read
Markdowner 是一个旨在帮助开发者将任何网站转换为LLM(大型语言模型)可用的Markdown数据的快速工具。这一工具不仅提高了数据结构的可预测性,还提升了AI应用中的查询响应质量。
项目名称
Markdowner
项目简介
Markdowner 是一个开源的Python工具,专门设计用于将网站内容转换成符合LLM需求的Markdown格式数据。该工具快速且易于部署,并且完全免费。其目标是为用户提供一种简单高效的方法来存储和查询网站内容,以进一步应用于AI项目中。
主要功能
- 将任意网站转换为Markdown:无论是简单的博客还是复杂的文档网站,Markdowner 都能够轻松转换。
- LLM过滤:过滤掉不必要的信息,使转换后的数据更适用于LLM处理。
- 详细Markdown模式:提供包含完整HTML内容的详细响应。
- 自动爬虫功能:无需站点地图,自动爬取子页面。
- 支持文本和JSON响应:根据需要切换不同的响应类型。
- 易于自主托管:简单的部署步骤,便于开发者自行托管。
使用场景
- 网站内容存储与查询:适用于需要存储和查询大量网页内容的AI项目,如Supermemory等应用。
- 数据转化与整理:帮助开发者高效地将非结构化数据转换为结构化Markdown格式,方便后续处理。
- 信息过滤与提取:利用LLM过滤功能,提取出关键信息,提升数据的质量和可用性。
- 自定义爬虫需求:自动爬取和转换多个子页面,适用于需要处理大规模网站内容的开发者。
项目地址
- GitHub 仓库:Markdowner GitHub Repository
使用示例
要使用API,只需发送GET请求到 https://md.dhr.wtf
使用示例:
$ curl 'https://md.dhr.wtf/?url=https://example.com'
必需参数
url(string): 要转换为Markdown的网站URL。
可选参数
enableDetailedResponse(boolean: false): 是否返回包含完整HTML内容的详细响应。crawlSubpages(boolean: false): 爬取并返回最多10个子页面的Markdown内容。llmFilter(boolean: false): 使用LLM过滤不必要的信息。
响应类型
- 添加
Content-Type: text/plain到头部以获得纯文本响应。 - 添加
Content-Type: application/json到头部以获得JSON响应。
技术细节
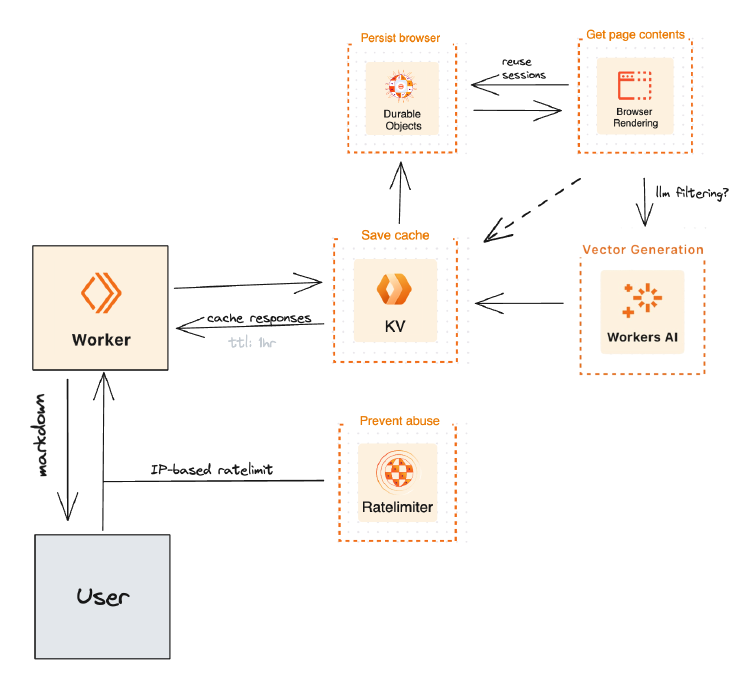
Markdowner 使用 Cloudflare 的 浏览器渲染 和 持久对象 来生成浏览器实例,并通过 Turndown 将内容转换为Markdown格式。
自主托管
您可以轻松自主托管这一项目。需要 Workers 付费计划来使用浏览器渲染和持久对象功能。
-
克隆仓库并下载依赖
git clone https://github.com/dhravya/markdowner npm i -
运行以下命令:
npx wrangler kv:namespace create md_cache -
打开
Wrangler.toml修改相应的ID -
运行
npm run deploy -
就可以开始使用了 👍
- Tags:
- Ai-News
- Markdowner