Crawl4AI: 开源的Web爬虫与数据提取解决方案,完美适用于LLM与AI应用
探索Crawl4AI,这款开源的Web爬虫和数据提取工具,为你的LLM和AI应用提供最优质的网页信息

- defagi
- 1 min read
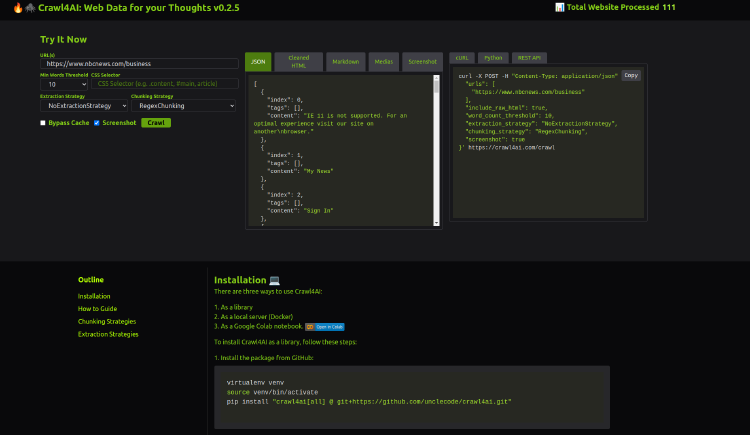
Crawl4AI 是一款开源Web爬虫和数据提取工具,旨在简化网页数据的爬取与提取过程,使其更易于大型语言模型(LLM)和AI应用程序的使用。无论你是开发者、数据科学家,还是AI研究者,Crawl4AI都能为你提供高效的网页数据获取方案。
github地址: https://github.com/unclecode/crawl4ai
体验地址: https://crawl4ai.com/
主要特点
- 高效的Web爬取:从网站上提取有价值的数据,确保抓取过程高效顺畅。
- 对LLM友好的输出格式:支持JSON、清洁的HTML、Markdown格式,确保数据易于集成。
- 多URL支持:可同时爬取多个URL,提高数据获取效率。
- 媒体标签处理:用ALT标签替换媒体标签,确保文本内容完整。
- 完全免费且开源:无任何使用费用,代码开放供社区使用和改进。
- 自定义JavaScript执行:在爬取之前执行自定义JavaScript,满足复杂的页面处理需求。
- 分块策略:支持基于主题、正则表达式、句子等多种分块策略。
- 高级提取策略:提供余弦聚类、LLM等高级策略,确保数据提取的准确性和相关性。
- CSS选择器支持:利用CSS选择器,精准提取网页中的特定内容。
- 指令/关键字优化:通过传递指令或关键字,优化数据提取过程。
使用指南
安装和配置 Crawl4AI的安装过程简便灵活,可选择多种方式进行安装:
- 作为Python库
- 作为本地服务器(使用Docker)
- 通过REST API
- 使用Google Colab笔记本
高级功能 除了基础爬取和提取功能,Crawl4AI还支持多种高级功能:
- 余弦聚类和LLM:提供高级的数据提取策略,确保数据提取的精确性和相关性。
- 自定义JavaScript:允许用户在爬取之前执行自定义JavaScript,以处理复杂的页面交互和动态内容。
- 关键字过滤:使用关键字过滤数据,确保提取到的只是你需要的信息。
- CSS选择器:支持CSS选择器,精准定位并提取网页中的特定内容。
结语
Crawl4AI是一款非常强大且易于使用的Web爬虫和数据提取工具,完全免费且开源。通过其灵活的安装选项、高效的爬取机制和对LLM友好的输出格式,它为AI和LLM应用提供了一个理想的数据获取解决方案。如果你正在寻找一款能够高效提取网页数据的软件,那么Crawl4AI绝对是不二之选。