AI制作有声小说之edge-tts
探索利用最新的文本转语音技术edge-tts制作有声小说,以《斗破苍穹》为例,分享从文本朗读到广播剧制作的过程与经验。

- defagi
- 2 min read
随着许多优秀的开源文本转语音(Text-to-Speech, TTS)项目的涌现,想尝试下使用AI制作有声小说。首先使用抖音口播常用的文本语音工具测试下,直接朗读《斗破苍穹》小说。随后尝试广播剧形式,虽然音效使用AI不好搞,最终保留了旁白和对话。通过ChatGPT写广播剧本,精简角色,保留旁白和主角进行测试
原文朗读效果:
旁白+对白的效果:
选择合适的文本转语音工具
在尝试制作有声小说之前,首先需要选择一个合适的文本转语音(TTS)工具。经常使用抖音时,会听到类似于云希口播的声音。经过搜索,我发现了一个开源的 edge-tts 工具,它可以用Python编写,使用起来非常方便,避免了网页版的复制粘贴麻烦。
后续可以尝试下:
这是我收录的一些开源文本转语音工具: https://nav.defagi.com/

初步测试:直接朗读小说
为了评估TTS工具的表现,我们以《斗破苍穹》小说为测试对象,直接将文本输入TTS工具进行朗读。测试结果表明,该工具能够较为自然地朗读小说文本,但在情感表达和语调变化上仍有提升空间。
确定了edge-tts工具后,需要对小说进行预处理:
-
按小说章节切分单独文件

-
处理章节内容,处理特殊字符或者符号,只保留逗号/句号
line.replace("\n","").replace("“","").replace(":"," ").replace("===","").replace(":"," ").replace("”","").replace(":"," ").replace(" ","") -
把章节内容再次分隔成200字左右的片段

-
对每个章节片段合成语音
cmd = "edge-tts --voice zh-CN-YunxiNeural --text \"{text}\" --write-media {media}.mp3 --write-subtitles {vtt}.vtt" def tts(txt_path): content = "" with open(txt_path,"r",encoding='utf-8') as f: content = f.read() split_content =content.split("\n\n\n") for index, item in enumerate(split_content): file_path =os.path.join("novel/chapter/1","wav",str(index)) exec_cmd=cmd.format(text=item,media=file_path,vtt=file_path) subprocess.run(exec_cmd, shell=True) time.sleep(2) -
把每个章节的语音片段合成完整的章节语音
ffmpeg -f concat -safe 0 -i input.txt -c copy all.mp3
合成后的效果:
尝试制作广播剧形式
有声小说不仅仅是单纯的朗读,更高阶的形式是广播剧,它结合了音效、配乐和多角色对话,能够带给听众更强的代入感。然而,在尝试使用AI制作广播剧时,我们发现音效的生成和处理较为复杂,难以达到预期效果。因此,我们决定简化制作流程,仅保留旁白和对话。
使用chatgpt制作脚本:
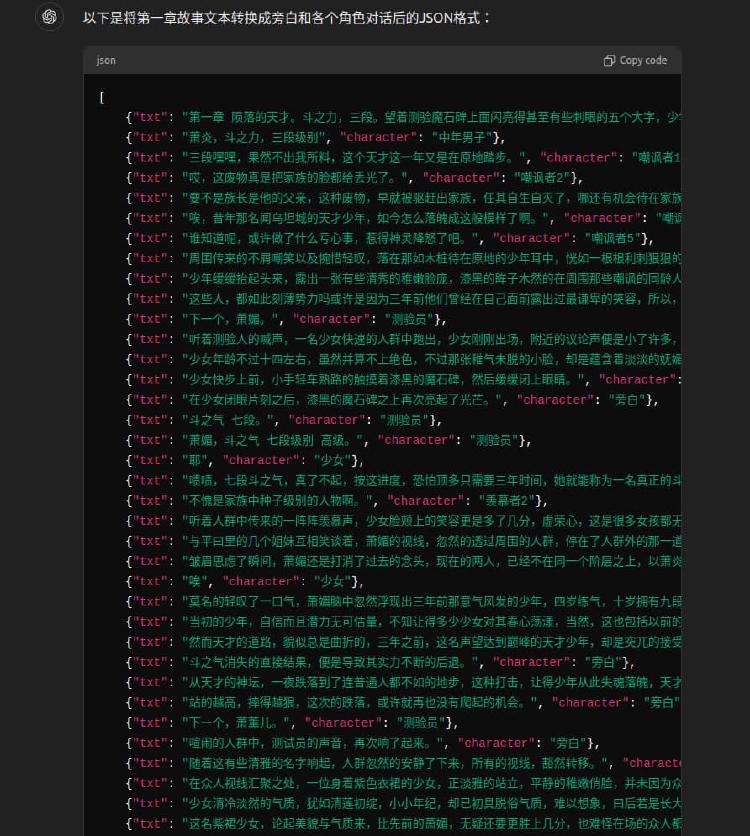
角色: 你是一位专业的剧本编辑,擅长将故事文本转化为适合舞台或屏幕的剧本格式。
技能: 剧本编辑、角色分析、文本转换、JSON格式处理。
目标: 你需要将一个故事转换成旁白和各个角色的文本,并且希望最终的输出格式是JSON。
限制条件: 确保转换的文本保留故事的原意,并且角色对话清晰、易于理解。
输出格式: JSON格式(python可解析),包含旁白和各个角色的对话。
工作流程:
- 阅读并理解原始故事文本。
- 将故事文本分解为大段的旁白和丰富角色对话。旁白应确保听众能够理解故事,包含细节、引人入胜。角色分配的 character 要符合角色身份。
- 将旁白和角色对话格式化为JSON。
示例:
故事文本: "在一个遥远的王国里,有一位勇敢的骑士和一位美丽的公主。有一天骑士遇到了公主。骑士说道:公主你真漂亮!。“谢谢你 亲爱的骑士先生”"
转换后的JSON格式:
[
{"txt": "在一个遥远的王国里,有一位勇敢的骑士和一位美丽的公主。有一天骑士遇到了公主。", "character": "旁白"},
{"txt": "骑士说道", "character": "旁白"},
{"txt": "公主你真漂亮!", "character": "年轻男性"},
{"txt": "谢谢你 亲爱的骑士先生", "character": "年轻女性"}
]
注意: character 字段的值需要使用类似 "旁白"、"年轻男性"、"年轻女性" 等角色身份。如果有多个角色,可以使用 "年轻男性1"、"年轻男性2" 等。
--故事文本--

精简角色:保留旁白和主角
为了进一步简化制作,决定保留两个主要角色:旁白和主角。使用ChatGPT生成的广播剧本,发现角色过多会导致对话复杂度增加,且语音合成的效果难以保证。因此,精简后的广播剧本仅包含旁白和主角的对话,既简化了制作流程,又保证了TTS工具的语音质量。
-
文本预处理如上步骤 1,2
line.replace("\n","").replace("“","").replace(":"," ").replace("===","").replace(":"," ").replace("”","").replace(":"," ").replace(" ","") -
根据生成脚本,逐步合成语音
default_voice = "zh-CN-YunxiNeural" character_dic={"旁白":"zh-CN-YunjianNeural","萧炎":"zh-CN-YunxiNeural",} s =json.loads(txt) cmd = "edge-tts --voice {character} --text \"{text}\" --write-media {media}.mp3" for index, item in enumerate(s): file_path =os.path.join("wav",str(index)) character = item["character"] text = str(item["txt"]).strip() exec_cmd=cmd.format(character=character_dic.get(character,default_voice),text=text,media=file_path) subprocess.run(exec_cmd, shell=True) time.sleep(2) -
把旁白,对话片段合成完整的章节语音
ffmpeg -f concat -safe 0 -i input.txt -c copy all_script.mp3
合成效果:
- Tags:
- Text-to-Speech
- Edge-Tts