使用chat-tts制作有声小说或口播语音
使用本地部署chattts制作有声小说过程,可用于口播语音合成

- defagi
- 2 min read
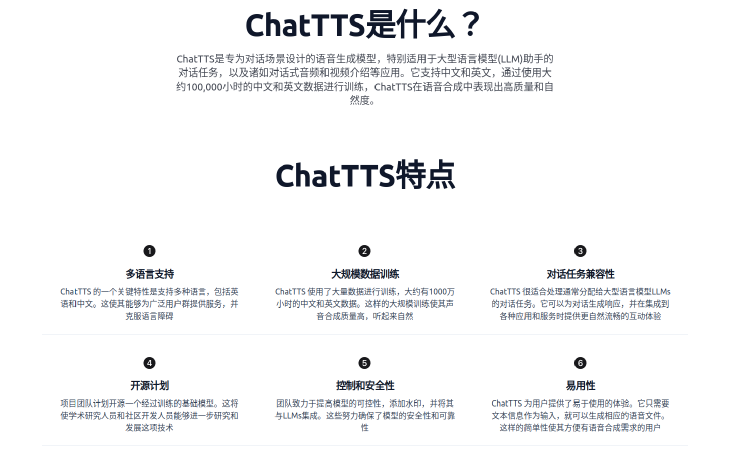
上一篇使用edge-tts制作有声小说,感觉还可以.如果使用python编写脚本是可以自动化合成有声小说的. 本次尝试使用Chattts制作有声小说.最终合成的效果往往存在音色不稳定、音量波动等问题。为了解决音色不稳定问题,我尝试了ChatTTS-Forge工具进行语音增强,有了少许提升.
以下是从本地部署ChatTTS/ChatTTS-Forge环境开始,经历了文本预处理、初步语音合成、音质优化的制作过程.
ChatTTS本地安装部署
如果本地有GPU,请先安装好CUDA/cuDNN环境
安装过程中出现问题可以去看下 issues
- 克隆仓库
git clone https://github.com/2noise/ChatTTS
cd ChatTTS
- 安装依赖
conda create -n chattts
conda activate chattts
pip install -r requirements.txt
- 快速启动
首次启动时会自动下来模型参数,会比较慢
python examples/web/webui.py

- 参数说明
- params_refine_text
prompt: 控制文本内容的口头化的程度(输入文本 -> 加了口头词的文本)
[oral_i]:控制文本口语化程度,i范围为 0-9,数字越大,添加的“啊”、“就是”、“那”之类的口头词越多;
[laugh_i] : 控制文本中添加笑声的程度,i范围为 0-9,值越大,笑声越多;
[break_i] : 控制文本中添加停顿的程度,i范围为 0-9,值越大,停顿越多;
top_P: 控制音频的情感相关性,范围为 0.1-0.9,数字越大,相关性越高
top_K: 控制音频的情感相似性,范围为 1-20,数字越小,相似性越高
temperature: 控制音频情感波动性,范围为 0-1,数字越大,波动性越大- params_infer_code 控制语音的生成(文本 ->语音 code)
spk_emb: 高斯采样得到的一个[1, 768]的向量,控制说话人的音色。
制作有声小说
数据预处理看参考 AI制作有声小说之edge-tts
-
按小说章节切分单独文件
-
处理章节内容,处理特殊字符或者符号,只保留逗号/句号
-
把章节内容再次分隔成200字左右的片段
处理后的内容:

-
把片段合成语音
直接只用webui很难找到合适的音色.然后从ChatTTS_Speaker中挑选了一个. 写一个python 脚本生成语音:
def tts(txt_path): chat = ChatTTS.Chat() chat.load_models(source="huggingface",compile=False) # Set to True for better performance spk = torch.load("seed_11_restored_emb.pt") params_infer_code = { 'spk_emb': spk, 'prompt': f'[speed_3]', 'top_P': 0.7, 'top_K': 20, 'temperature': .3 } params_refine_text = { 'prompt': '[oral_2][laugh_0][break_6]', 'top_P': 0.7, 'top_K': 20, 'temperature': .3 } content = "" with open(txt_path,"r",encoding='utf-8') as f: content = f.read() split_content =content.split("\n\n\n") wav_all = [] for index, item in enumerate(split_content): wav_file =os.path.join("novel/chapter/1","wav",str(index)+".wav") texts = [item] wavs = chat.infer(texts, use_decoder=True, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code) wav_all.append(torch.from_numpy(wavs[0])) torchaudio.save(wav_file, torch.from_numpy(wavs[0]), 24000) combined_wav = torch.cat(wav_all, dim=1) torchaudio.save("novel/chapter/1/1.wav", combined_wav, 24000)合成后的效果:
试听了下ChatTTS合成的有声小说效果,感觉很不理想,发现如下问题:
- 音色还是存在不稳定的情况,长句子有概率出现英文
- 音量有时会忽高忽地
- 短句子发音不准确
- 有时语音会出现电流声
- 语音最后有概率混杂其他声音
感觉如果加上语音增强可能可以解决音量忽高忽地问题,于是又试了下 ChatTTS-Forge
-
ChatTTS-Forge语音合成

ChatTTS-Forge语音合成效果:
相对与没有语音增强的稳定性好了些.其他问题还是概率性出现.
-
ChatTTS-Forge API语音合成
使用webui中很难解决那些概率性问题,最好的方式是重复执行几遍,人工挑选合适的语音,在使用ffmpeg手动合成完整的语音.
with open("zz01.json","r",encoding="utf-8") as f:
txt = f.read()
default_spk = "正式"
spk_dic={"旁白":"旁白01","萧炎":"正式"}
# s =json.loads(txt)
# 解析JSON内容
data = json.loads(txt)
def json_to_speak(data):
url = "http://0.0.0.0:7870/v1/ssml"
# 生成<speak>标签内容
for index, item in enumerate(data):
speak_content = "<speak version='0.1'>"
character = spk_dic.get(item["character"],default_spk)
speak_content += f"<voice spk='{character}' seed='42'>"
speak_content += f"{item['txt']}[lbreak]"
speak_content += "</voice>"
speak_content += "</speak>"
print(speak_content)
payload = {
"ssml": speak_content,
"format": "mp3",
"batch_size": 4
}
headers = {
'Content-Type': 'application/json'
}
json_payload = json.dumps(payload)
response = requests.post(url, data=json_payload, headers=headers)
if response.status_code == 200:
# Save the MP3 file
indx = str(index)
with open(f'mp3/{indx}.mp3', 'wb') as f:
f.write(response.content)
print("MP3 file saved successfully.")
else:
print(f"Error: {response.status_code}")
print(response.text)
result = json_to_speak(data)
ChatTTS-Forge API语音合成效果:
- Tags:
- Text-to-Speech
- Chat-Tts